Claas Beger
Santa Fe Institute

I am currently a Graduate Fellow at Santa Fe Institute, doing research on multimodal reasoning under Professor Melanie Mitchell. Prior to that I finished my Master’s in Computer Science at Cornell University, where I worked with Kevin Ellis, Kilian Weinberger and Saikat Dutta. My research interest centers broadly around Human-like Artificial Intelligence. For this purpose, I think it is the most promising direction to look towards Natural Intelligence, both with regard to the brain and psychology/cognition.
I am applying to PhD programs for the fall 2025 cycle.
news
| Oct 03, 2025 | New paper on abstraction capabilities across modalities on ARC tasks out on arXiv! Also check out Melanie’s blog: https://aiguide.substack.com/p/do-ai-reasoning-models-abstract-and |
|---|---|
| Sep 22, 2025 | “Investigating Abstraction Capabilities of the o3 Model Using Textual and Visual Modalities” (Forthcoming) accepted as a Spotlight at Neurips Workshop Multimodal Algorithmic Reasoning! |
| Sep 22, 2025 | “Refining Inverse Constitutional AI for Dataset Validation under the EU AI Act” (Forthcoming) accepted at Neurips Workshop Regulatable Machine Learning! |
| Sep 22, 2025 | “A Neuroscience-Inspired Dual-Process Model of Compositional Generalization” accepted at Neurips Workshop Interpreting Cognition in Deep Learning Models! |
| Jun 21, 2025 | I won a Travel Award for my poster presentation at the 51st annual meeting of the Society of Philosophy and Psychology! |
selected publications
-
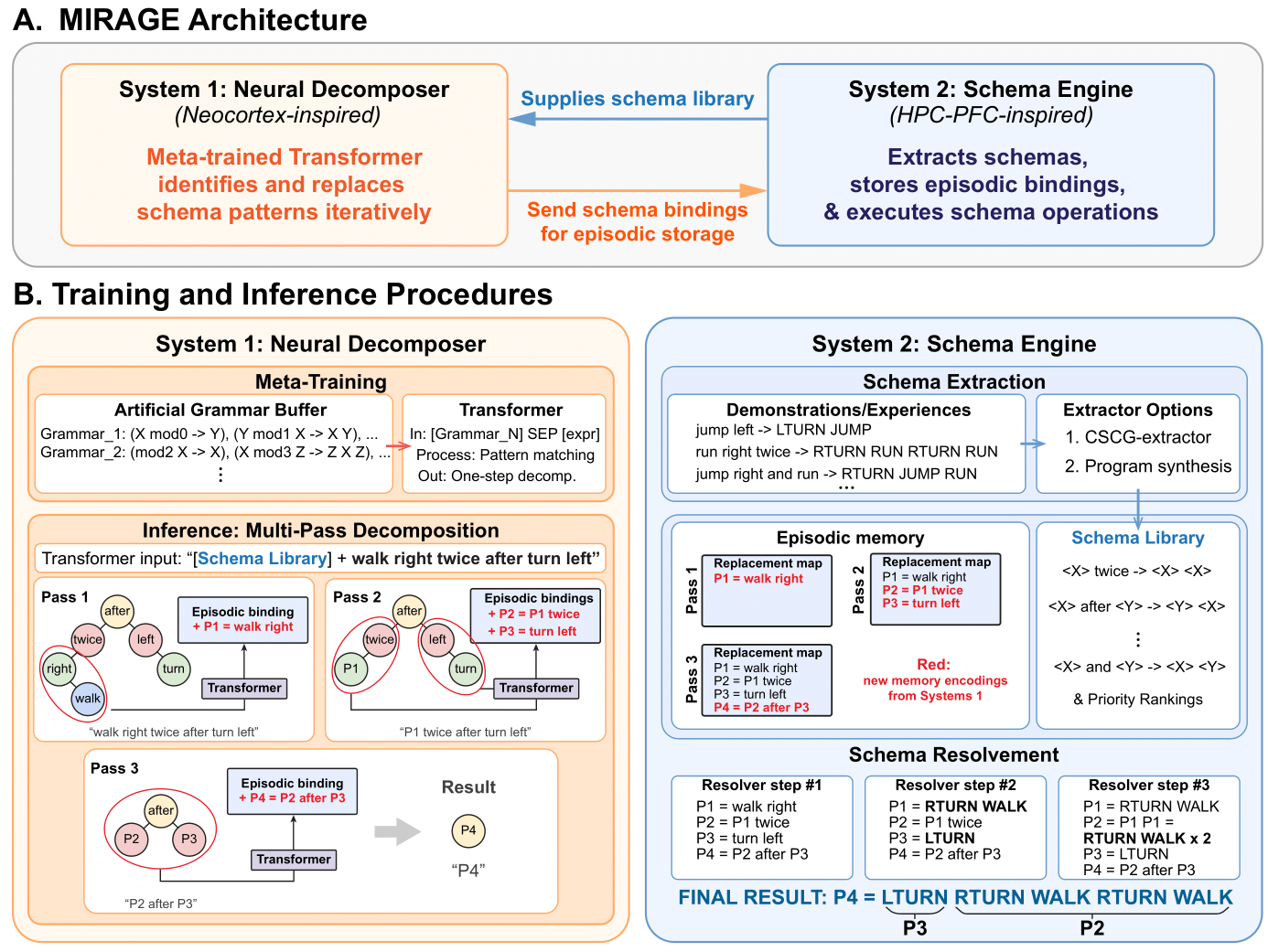 2025TLDR: An architecture of schema learning and iterative application can resolve arbitrarily deep compositional statements.
2025TLDR: An architecture of schema learning and iterative application can resolve arbitrarily deep compositional statements. -
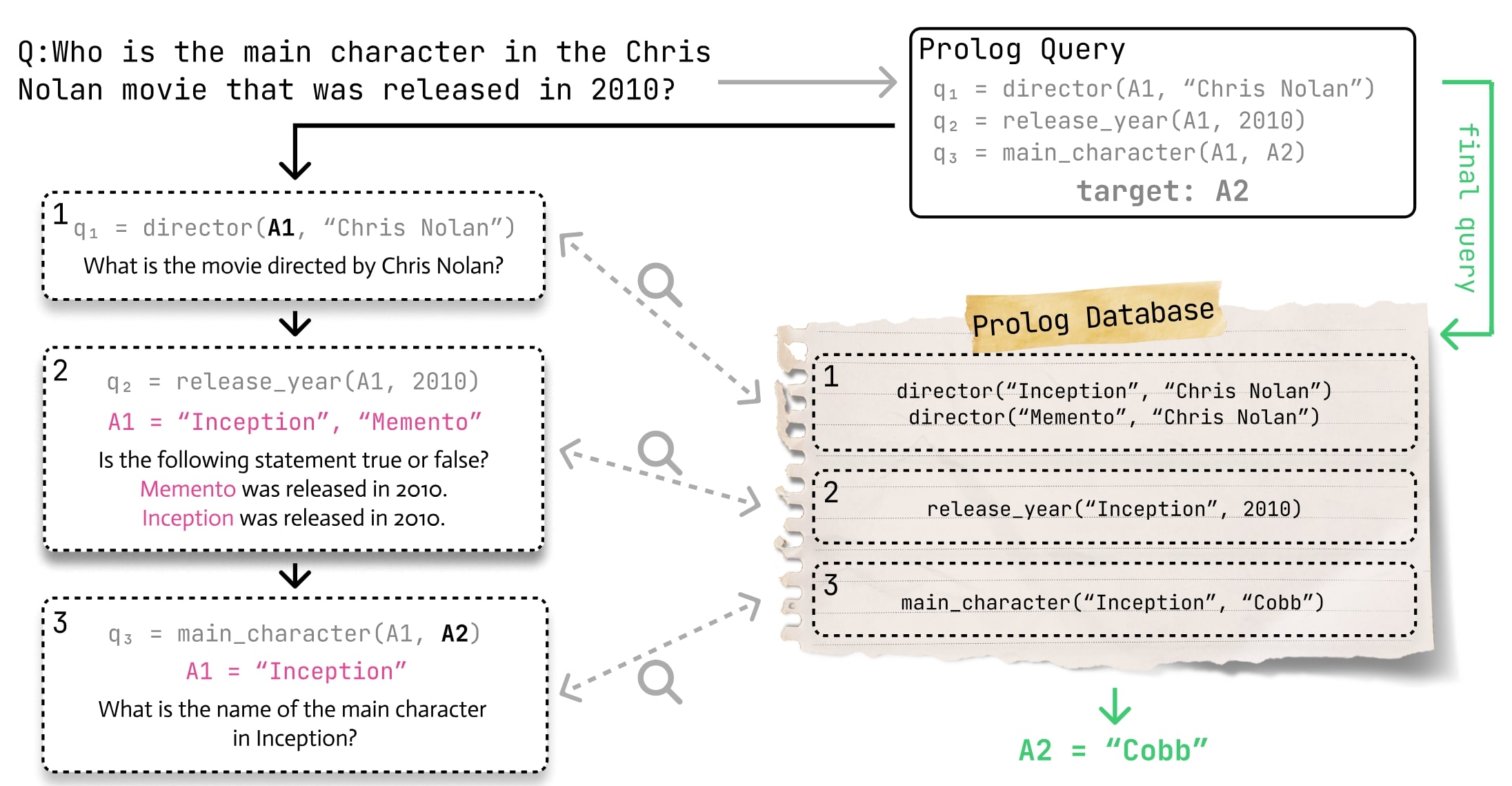 2025TLDR: Decomposing multi-hop questions into single-step prolog definition improves performance on various long-context question datasets.
2025TLDR: Decomposing multi-hop questions into single-step prolog definition improves performance on various long-context question datasets. -
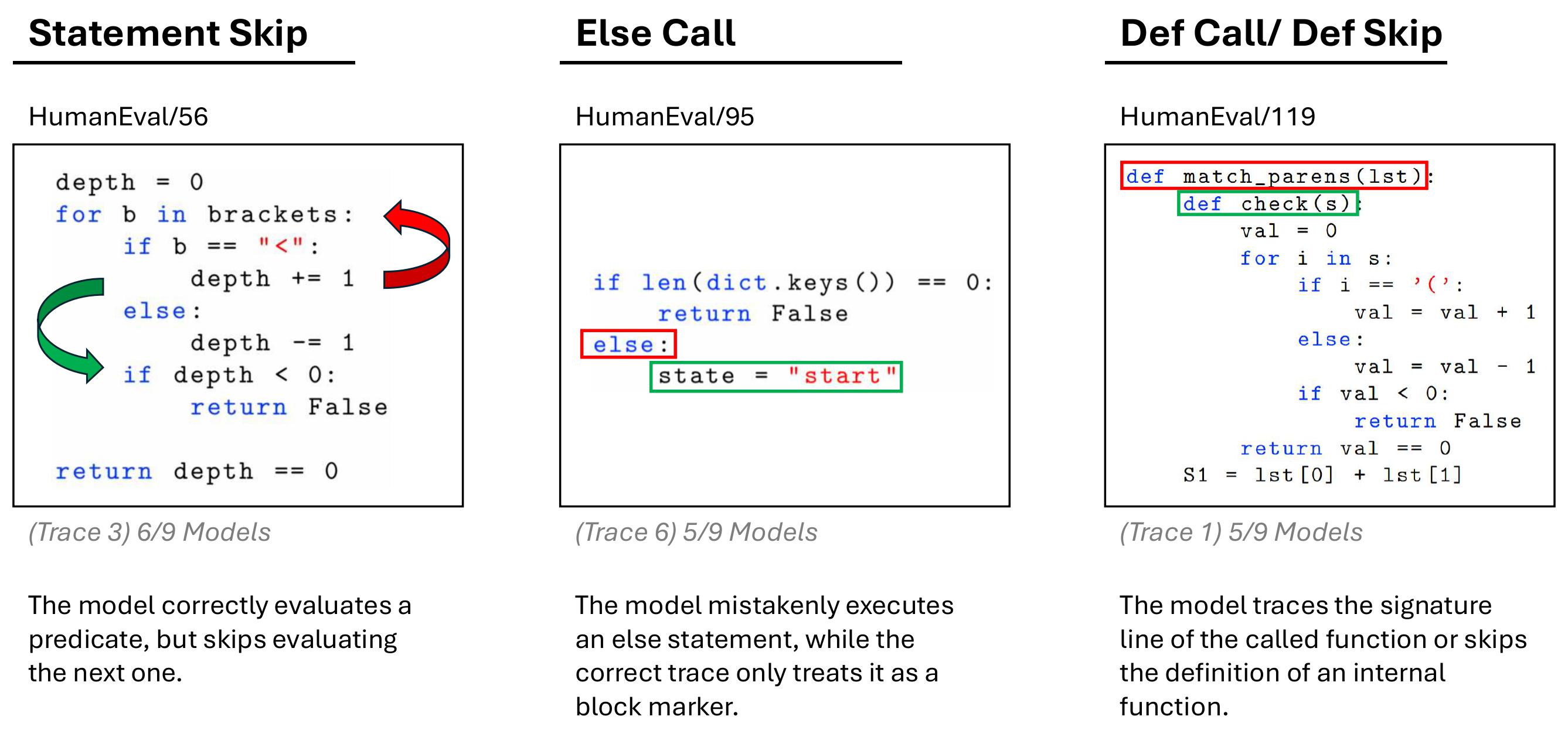 2025TLDR: Various language models struggle with dry-execution of simple and advanced code structures (Recursion, Concurrency OOP)
2025TLDR: Various language models struggle with dry-execution of simple and advanced code structures (Recursion, Concurrency OOP) -
 2025TLDR: Using improved clustering and a more diverse embedding approach our technique can more accurately compress preference datasets into human-readable constitutions
2025TLDR: Using improved clustering and a more diverse embedding approach our technique can more accurately compress preference datasets into human-readable constitutions -

-
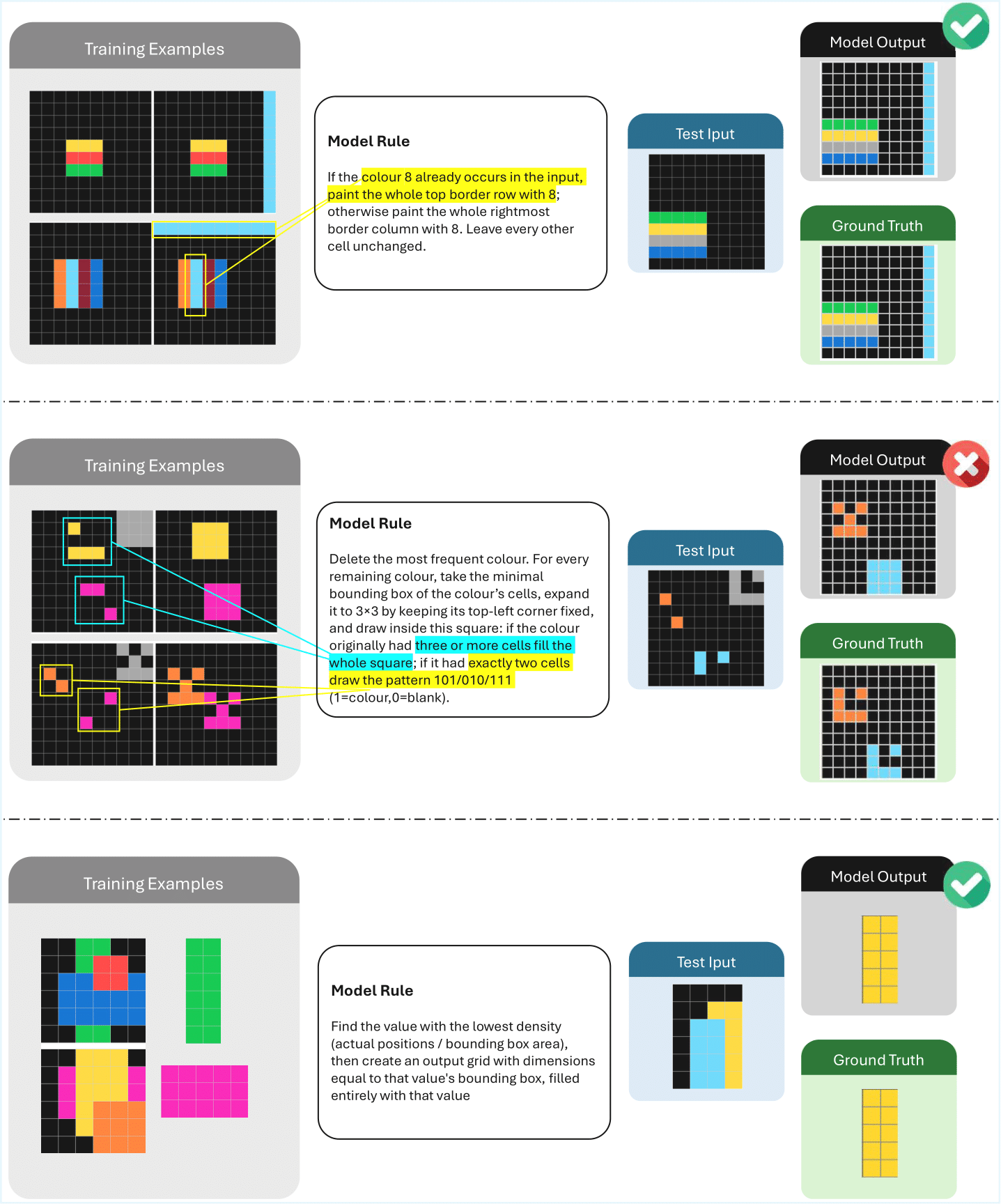 2025TLDR: Vision-Language models have good performance on abstract reasoning tasks, but do not utilize the intended human-core knowledge priors.
2025TLDR: Vision-Language models have good performance on abstract reasoning tasks, but do not utilize the intended human-core knowledge priors.